 Generate Any Scene
:
Generate Any Scene
:
Evaluating and Improving Text-to-Vision Generation with Scene Graph Programming
Abstract
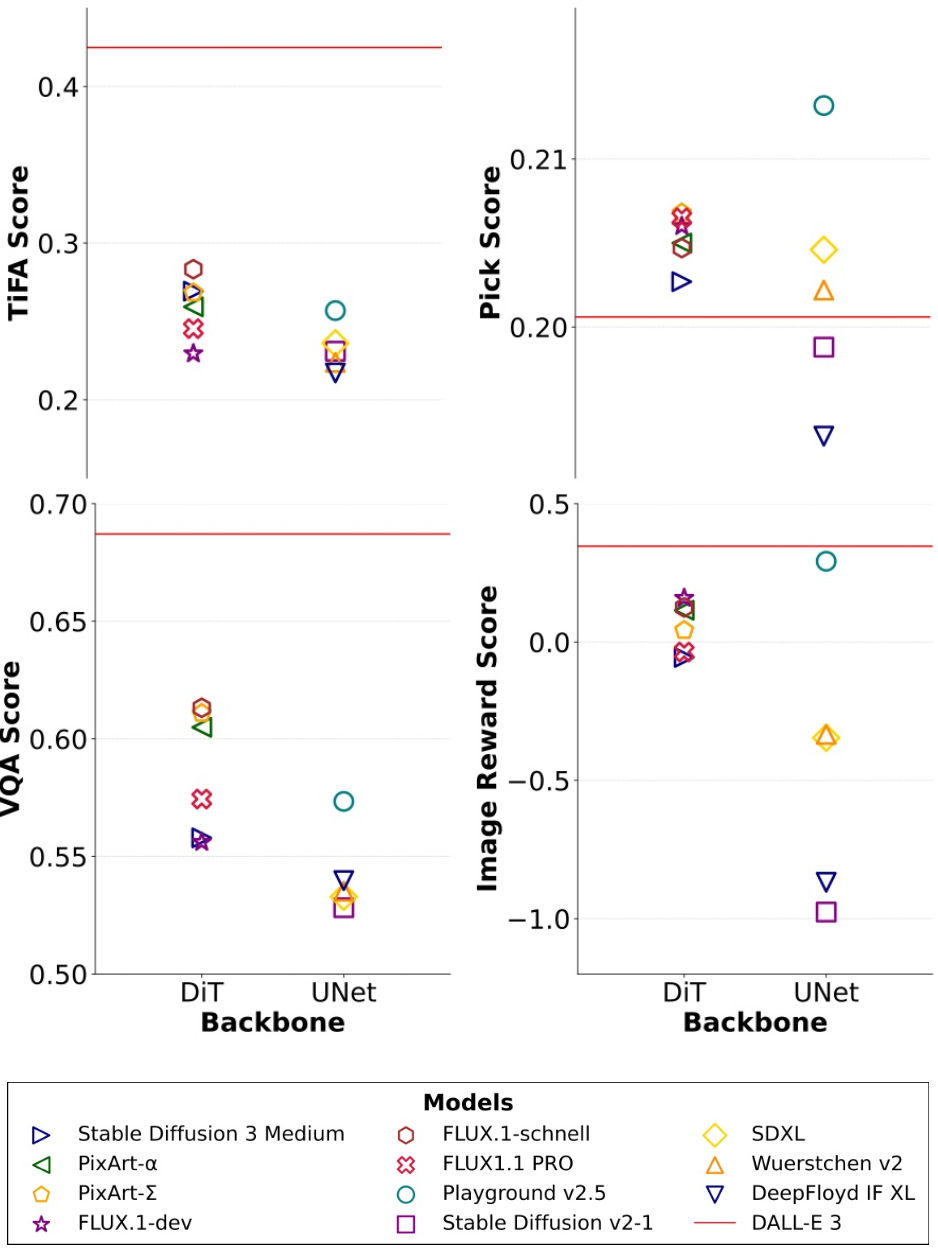
Generative models like DALL-E and Sora have gained attention by producing implausible images, such as “astronauts riding a horse in space.” Despite the proliferation of text-to-vision models that have inundated the internet with synthetic visuals, from images to 3D assets, current benchmarks predominantly evaluate these models on real-world scenes paired with captions. We introduce Generate Any Scene, a groundbreaking framework that systematically enumerates scene graphs representing a vast array of visual scenes, spanning realistic to imaginative compositions. Generate Any Scene leverages Scene Graph Programming: a revolutionary method for dynamically constructing scene graphs of varying complexity from a structured taxonomy of visual elements. This taxonomy includes numerous objects, attributes, and relations, enabling the synthesis of an almost infinite variety of scene graphs. Using these structured representations, Generate Any Scene translates each scene graph into a caption, enabling scalable evaluation of text-to-vision models through standard metrics. We conduct extensive evaluations across multiple text-to-image, text-to-video, and text-to-3D models, presenting key findings on model performance. We find that DiT-backbone text-to-image models align more closely with input captions than UNet-backbone models. Text-to-video models struggle with balancing dynamics and consistency, while both text-to-video and text-to-3D models show notable gaps in human preference alignment. Additionally, we demonstrate the effectiveness of Generate Any Scene by conducting three practical applications leveraging captions generated by Generate Any Scene:
- A self-improving framework where models iteratively enhance their performance using generated data.
- A distillation process to transfer specific strengths from proprietary models to open-source counterparts.
- Improvements in content moderation by identifying and generating challenging synthetic data.
Scene Graph Programming
Metadata
To construct a scene graph, we use three main metadata types: 28,787 objects, 1,494 attributes, and 10,492 Relationships. We also have 2,193 scene attributes that capture the board aspect of the caption, such as art style, to create a complete visual caption.Captions Generation Process
 The generation pipeline of Generate Any Scene:
The generation pipeline of Generate Any Scene:
Overall Results
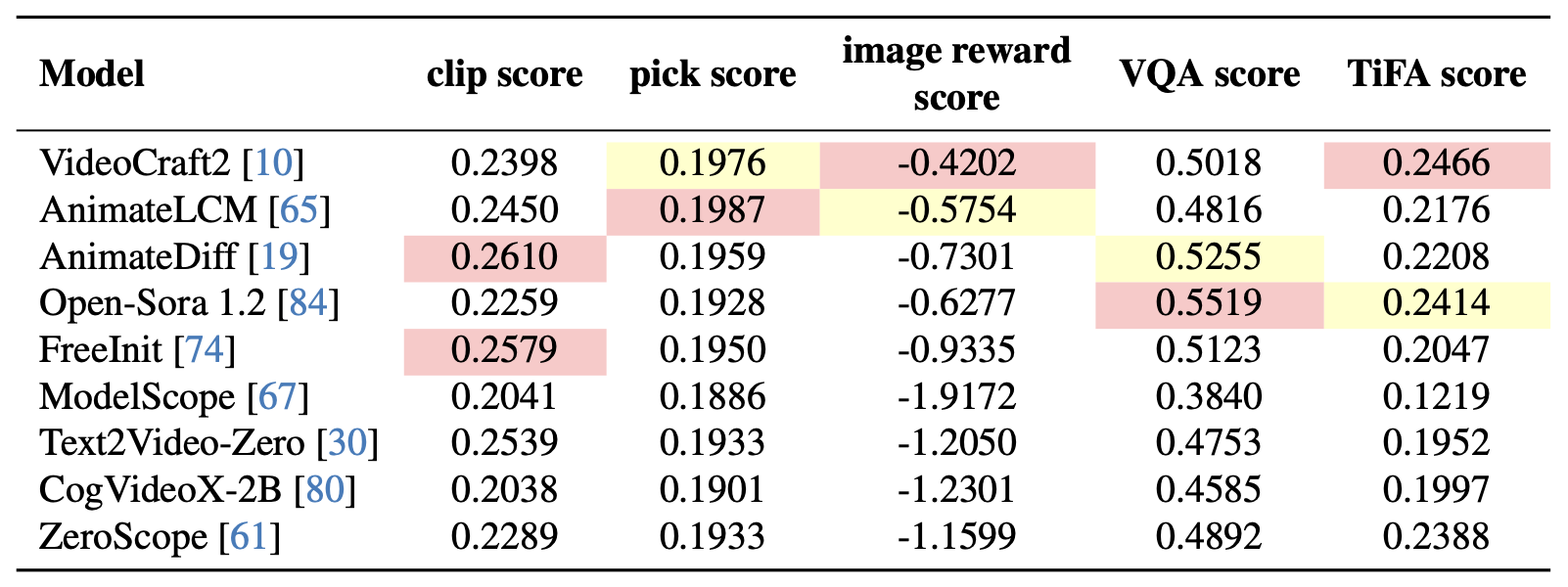
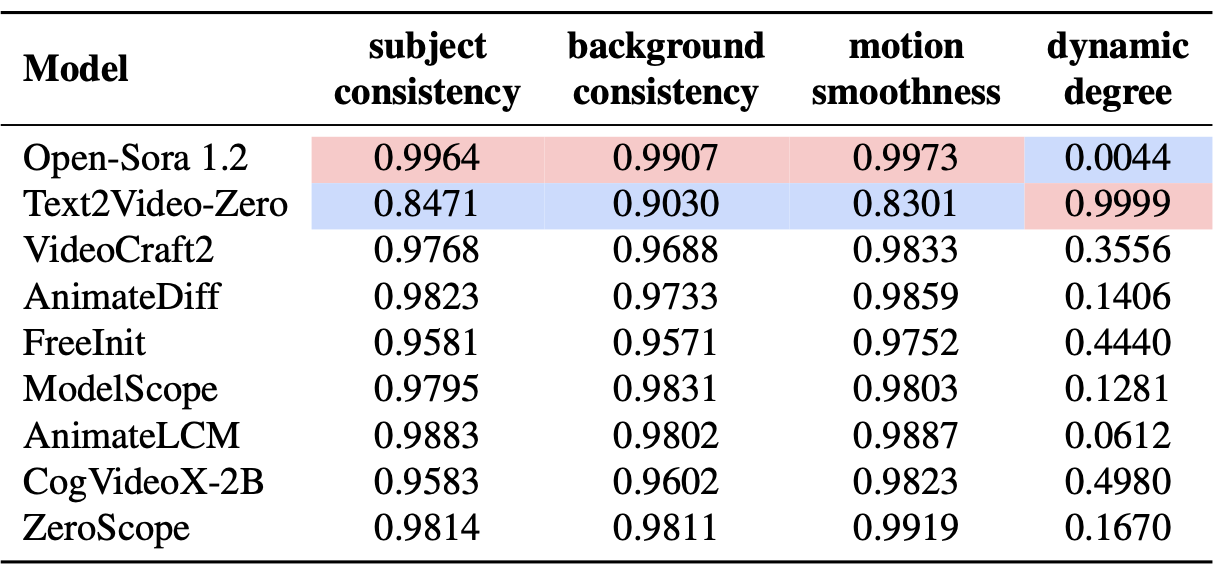
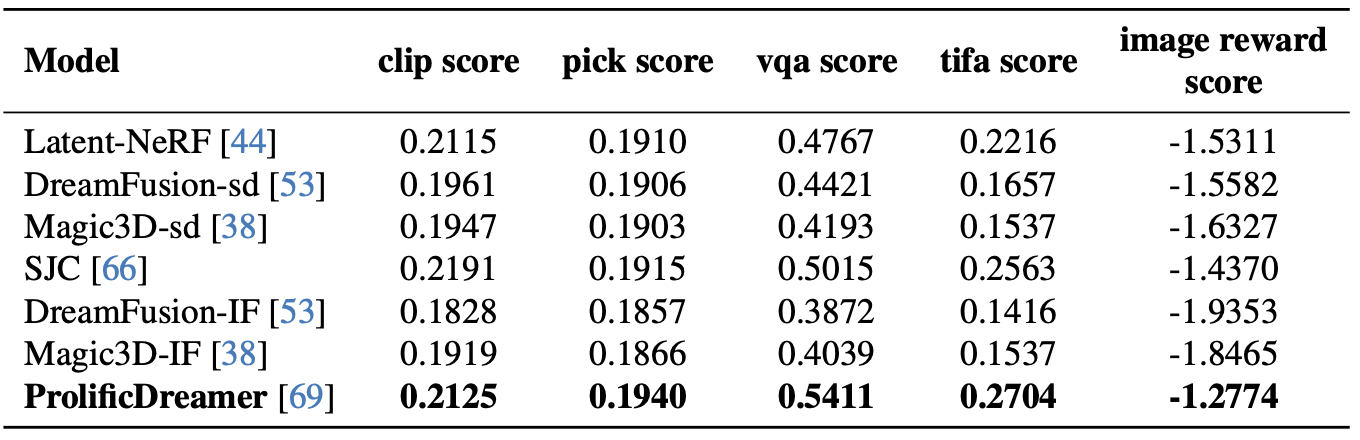
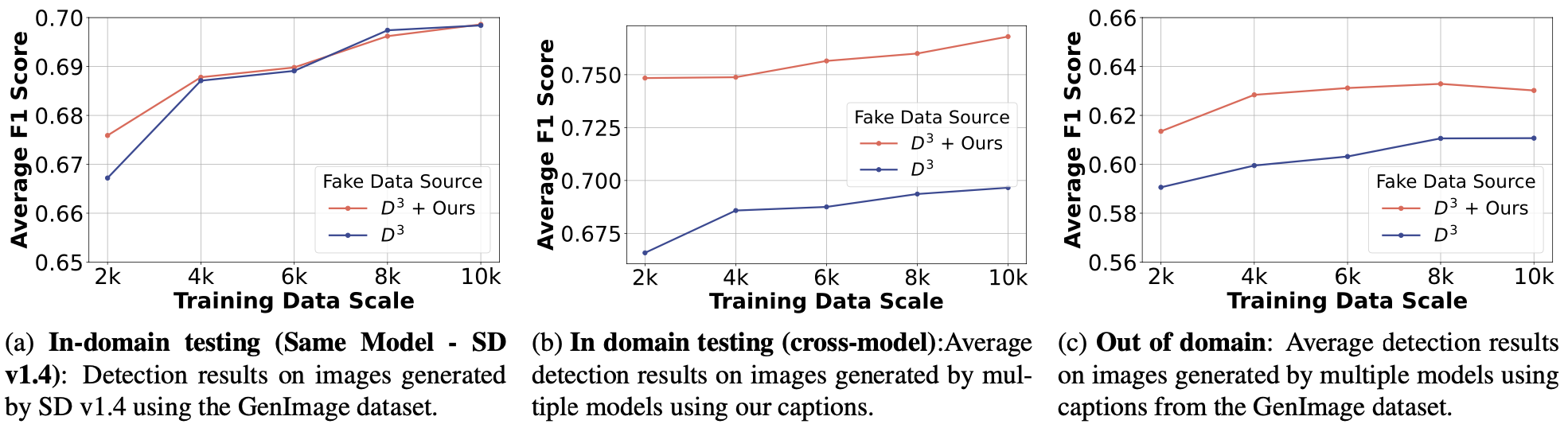
Application
 We propose three applications of Generate Any Scene.
We propose three applications of Generate Any Scene.
Application 1:
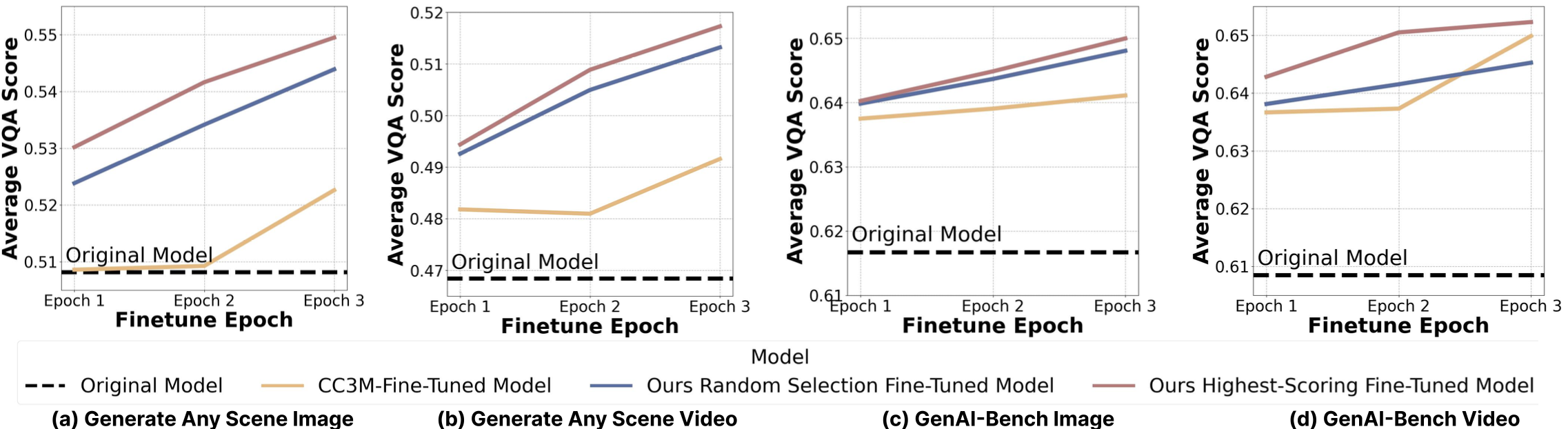
Application 2:

Application 3: